
你好,我是 Lnn!
这是我的个人技术博客,记录我的学习历程和技术分享。
联系方式
- 📧 Email: [email protected]
- 💻 GitHub: @759434091
- 🌐 网站: lohoknang.com
2026/3/15小于 1 分钟
你好,我是 Lnn!
这是我的个人技术博客,记录我的学习历程和技术分享。
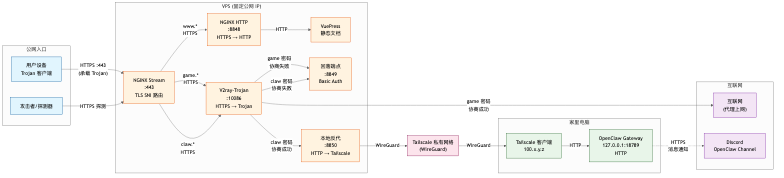
前提:你已有一台 VPS(境外,固定公网 IP)和一个域名。如果没有,这篇文章不用看了——不是目标读者。
用域名和 VPS 搭建一套隐蔽的远程访问通道,核心想法:让服务看起来像普通网站,只有通过正确的方式才能访问。
说明:本文以 OpenClaw 为例,这套架构同样适用于任何需要隐蔽访问的家庭服务(如 NAS 管理后台、Home Assistant、自建 Git 等)。

记录在闲置 MBP 上部署和使用 OpenClaw 的实践经验
阅读前须知:
如果你没有以下基础能力:
不建议自行搭建 OpenClaw,这超出了你的个人能力范围。
替代方案:
能翻墙不是一切的前提。各大互联网大厂都推出了自己各种各样形式的国产 Claw 部署方案。
能够在获得一个Map<String, *>数据集对象,对其进行java.util.BigDecimal"安全地"复杂数值计算的DSL提供。 DSL设计:
// get records
val records: Map<String, *> = querySql()
// do calculation
val result = calculate(records) {
(n("numerator") + n("numerator2")) / n("denominator")
}假设你已经了解了, Reactive Streams某一个实现库的基本使用。
Project Reactor是遵循Reactive Streams响应式流规范实现的超集,是一套事件驱动的、反应式、函数式异步编程库。
这是一套规范,也是一套SPI定义,目前地位和权威性非常高。
正如如JDBC一样理解,这一套规范有不同的实现,目前有Project Reactor、RxJava系列、JDK 9 Flow…
他们都可以通过Reactive Streams SPI相互转化
// Project Reactor
val mono = Mono.just(1)
// Reactive Streams
val pub = mono as Publisher<Int>
// RxJava
val maybe = Maybe.fromPublisher(pub)之前的博客系统自己写的,工作后也不想维护了。。。
直接迁移到尤大的VuePress去
创建文档信息的业务场景
public RestResult<DocumentDo> generate(Dto dto) {
RestResult<DocumentDo> result = new RestResult<>();
DocumentDo docDo = new DocumentDo();
// ...
// 检查重复
if(checkDuplicate(dto.getUsername())) {
throw new BizException("...");
}
// 各种 username 合法过滤, 关键词过滤, 可能涉及到修改username的
RpcResult<UsernameDto> usernameRes = xxxService.getUsername(username)
String finalUsername = null;
if(usernameRes != null &&
usernameRes.isSuccess() &&
usernameRes.getData() != null) {
finalUsername = usernameRes.getData().getUsername();
}
// 能不能看出来这段代码的问题?
docDo.setUsername(finalUsername);
// 取块 并开始处理
ContentDto richContentDto = dto.getContent();
if(richContent == null) {
throw new BizException("...");
}
List<BlockDto> blocks = richContentDto.getBlocks();
if(blocks == null) {
throw new BizException("...");
}
// encode & flattern images
List<BlockDo> blockDoList = blocks
.stream()
.parallel()
.flatmap(block -> {
if(!BlockUtils.isImage(block)) {
return Stream.of(block);
}
byte[] bytes = (bytes[]) block.getContent();
byte[][] bytess = ImageUtils.analysis(bytes);
return Arrays
.stream()
.map(bytes -> {
BlockDo blockDo = new BlockDo();
blockDo.setXXX(block.getXXX());
blockDo.setContent(bytes);
})
})
.collect(Collectors.toList());
// 假设整个文档流经历了黑盒一样的处理计算, 你会选择相信这个blockDoList吗
docDo.setBlocks(blockDoList);
DocumentDo docResDo = dockDoRepository.save(docDo);
result.setSuccess(true);
result.setDate(docResDo);
return result;
}中文描述是 Maven 增强插件,主要功能是编译的时候对一些"规则"进行检测,命中就会拦截抛错。当然排除依赖还是依赖 mvn dependency:tree -Dverbose 定位到去哪里排除。
看起来是给自己添麻烦,其实是一个管理整个 project 质量的很好工具,特别是在引入二方包的时候。
如代码,展示了
从应用开发者(即使用者)的角度, 从论文来理解思路和模型入门, 或者从API入门都好, 都不要从原理入门.
因为从原理入门, 一开始就会陷入各种实现, 以及解决各种有解又无解的分布式问题里面. 比如
各个框架的实现原理大框架都比较一致, 但是详细的实现差别很大, 而且寿命很短(spark storm升级几代实现了), 是极其容易被抛弃的, 不如把这个问题抛给产品的人员, 调优也交给他(给钱了的)
流式计算依据形态分为:
MapReduce借鉴了函数式编程的思想, 可以讲是分布式批处理的函数式实现。
但是map / reduce 的批处理模型只能对于有界流才能应用, 而对于无界流, 所有reduce原语都将失效, 如reduce, distinct, fold/collect, count, sum, average